



Using Python libraries with Scala in Spark

Apache Spark has grown to be a popular framework for big data processing. It is a powerful framework as it allows expressing logic in different programming languages like Java, Scala, Python & R.
However, there are use-cases which require using libraries from a different language than the one the application was written in. One such scenario is that a Spark application is written in Scala, but now there is a need for Python libraries. This is common as Python has a better ecosystem of libraries around statistics & machine learning. E.g., SciPy, NumPy etc.
How can we leverage Python libraries in a Scala Spark application?
Spark does have a Python API (PySpark), but its core is written in Scala. Let us think about how Spark achieves that.
Below is the high-level data flow between Python runtime and JVM (Scala runtime)
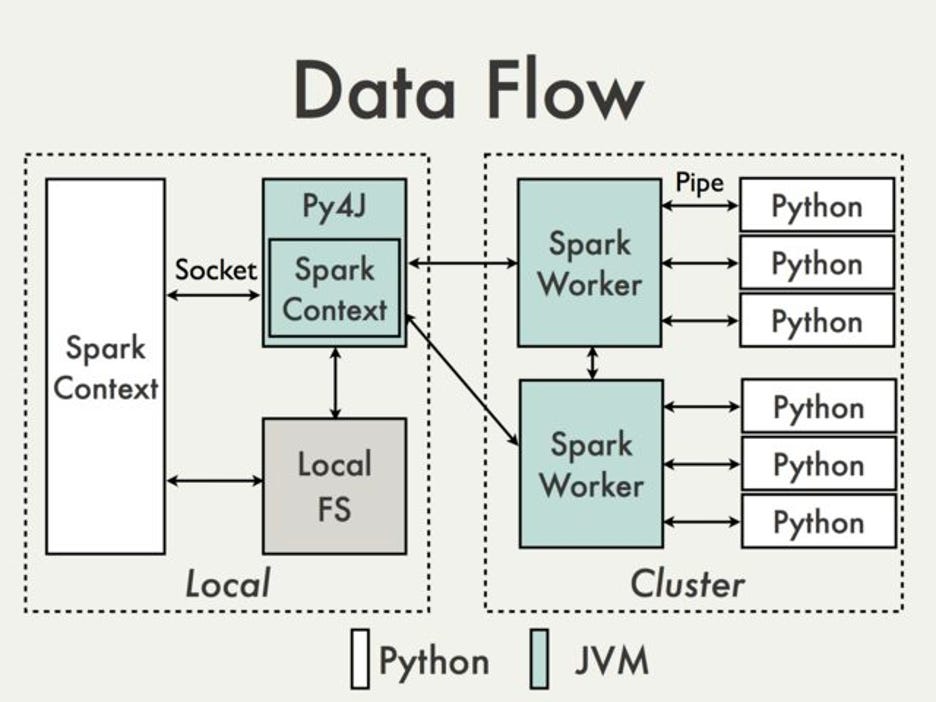
Spark leverages a library called Py4J, that allows invoking of JVM code from Python runtime. This communication happens over a socket in the driver.
We can re-use the same Py4J bridge to callback Python code from within the Scala code. Below is the data flow.
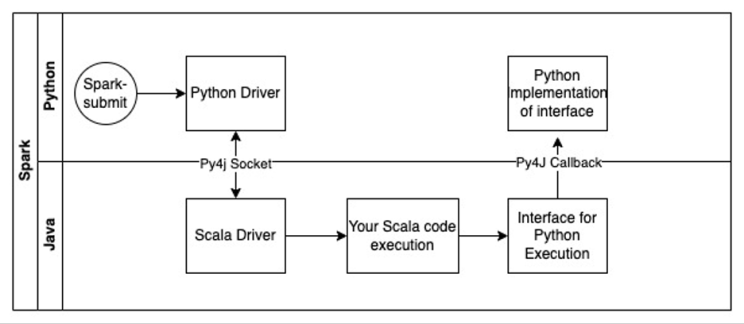
When spark-submit happens, it enters the Python driver code, which just invokes the Scala Driver code of your existing application. In your Scala application you would define an interface that can be defined inside the Python runtime. In this interface implementation in Python you can leverage whatever libraries you wish to use.
Pseudocode: Python Driver
from python_implementation import PythonImplementation
from pyspark.java_gateway import ensure_callback_server_started
sc = //Spark context
// This enables Java to call Python code
ensure_callback_server_started(sc._gateway)
python_implementation = PythonImplementation(sc._gateway, spark._wrapped)
scalaDriver = new jvm.your.scala.Driver(python_implementation)
scalaDriver.execute(spark._jsparkSession)Pseudocode: Scala Interface Definition that Python Implements
trait PythonImplementation {
def process(df: DataFrame): DataFrame
}Pseudocode: Scala Driver
def execute(sparkSession: SparkSession) = {
scDf = //some dataframe
pythonEvaluation.evaluate(scDf)
}Pseudocode: Python Implementation
class PythonImplementation(object):
def __init__(self, gateway, sql_context):
self.gateway = gateway
self.sql_context = sql_context
def process(self, df):
// Your Python logic
class Java:
implements = ['your.PythonImplementation']Caveats
The solution relies on Spark private variables like _jvm, _gateway etc., which may break the solution in future versions of Spark
This does not and is not intended to solve performance problems with Python UDFs
Follow me on LinkedIn